 A special lecture was given at the Lodge by Elena Yegorova on “Data Granulation in Pattern Recognition”.
A special lecture was given at the Lodge by Elena Yegorova on “Data Granulation in Pattern Recognition”.
Elena graduated with a Master from Wessex Institute before completing a PhD degree at Kharkov National University in Ukraine where she is now an Associate Professor. Her duties include teaching information technology and carrying out research in the field of pattern recognition, using granulation methods.
Granulation is an important topic for data acquisition as it helps to identify different objects. Granular capacity is actively applied in computational intelligence, information based on rough sets, internal data analysis and many other applications. The identification requires other tools such as linkage, i.e. a set of formal operations and linkages.
The method has a wide range of applications. Its accuracy and speed was tested in a series of database samples. The idea has important advantages in data retrieval systems.
The work is proceeding at the Pattern Recognition Laboratory of Kharkov National University searching for more accurate and reliable results. The Laboratory carries out consulting work for industry and foreign countries as well as basic research in this important topic.
The presentation was illustrated with a series of examples and followed by a lively discussion.
Data Granulation in Pattern Recognition
Internal, external and contextual properties of granules, collective structure of a granules families and hierarchical structure of granules represent a possible foundation for qualitative/ quantitative characterization of levels of abstraction, detail, control, explanation, difficulty, organisation and so on. Granular computing are actively used in computational intelligence, information granulation based on rough sets, data mining, interval analysis, cluster analysis, machine learning. Need for tools providing a granular linkage, i.e. formal operations and relations determined on granules.
The explosion of image content is closely connected with segmentations efficiency. Segmented images are formed from an input image by gathering its elements into sets likely to be associated with meaningful objects in the scene. That is, the main segmentation goal is to partition the entire image into disjoint connected or disconnected regions. Unfortunately, the effectiveness of their direct interpretation heavily depends on the application area and characteristics of the acquisition system. Possible high-level region-based interpretations are associated with some a priori information, measurable region properties, heuristics, and plausibility of computational inference. Whatever the case, it is often necessary to have dealings with a whole family of partitions and we have to be able to compare these partitions produced e.g. by a variety of segmentation algorithms. At least splitting and merging techniques make us to match segmentation results, which may ultimately correspond to indirect image comparisons.
There exists an impressive amount of approaches to measure proximities (or dissimilarities) between images in feature or signal spaces. Distance functions (metrics) satisfy requirements of all applications to the utmost. However, the expansion of content-based image and video retrieval systems allows us to draw an inference that problems of metrics assortment and ground are far from being fully explored. We propose and vindicate a new metric providing all partitions (and consequently images) matching.
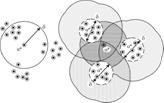
Metric on partitions allows us to compare objects with different levels of detalizations and also make objects search independent of the complex background.

Different levels of detalization
 Also proposed is a new indexing method in metric space which transforms distance matrix into block-diagonal form by certain compactness criteria and predicts the maximum number of distance evaluations at the search stage what hasn’t yet been done by any of known indexing methods. It is emphasized that the method does not rely on pivot selection strategy: its construction policy is aimed at creation of compact blocks minimum number with distance between any elements of the block less then predefined threshold value. Later the capacity of those blocks can be refined by solving the optimization task.
Also proposed is a new indexing method in metric space which transforms distance matrix into block-diagonal form by certain compactness criteria and predicts the maximum number of distance evaluations at the search stage what hasn’t yet been done by any of known indexing methods. It is emphasized that the method does not rely on pivot selection strategy: its construction policy is aimed at creation of compact blocks minimum number with distance between any elements of the block less then predefined threshold value. Later the capacity of those blocks can be refined by solving the optimization task.